Discovery‑stage oncology decisions depend on understanding how disease is diagnosed, treated, and progresses in real‑world clinical practice. Yet traditional data sources rarely provide the clinical depth, longitudinal continuity, or population clarity needed at this stage.
BC Platforms enables early asset teams to define oncology patient populations and treatment pathways using clinically rich, multi‑modal real‑world data sourced from hospitals and centers of excellence worldwide. This supports earlier, more confident discovery‑stage decisions on patient targeting, opportunity assessment, and development strategy across key evidence‑generation markets.
What’s at stake
At the discovery stage, teams must make decisions before a comprehensive understanding of a cancer’s real‑world presentation and management is established. This includes defining target patient populations, estimating opportunity size, understanding current treatment pathways, and identifying where unmet need remains.
Without access to high‑quality, multi‑modal patient data, early asset teams risk:
Inaccurate estimates of incidence, prevalence, and diagnosed populations
Limited understanding of pathways to diagnosis
Incomplete visibility into real‑world treatment pathways
Failure to identify clinically relevant patient sub‑types, including disease severity, co‑morbidities, and molecular characteristics
Incomplete insights to variations across geographies
Inability to assess outcomes and identify areas of unmet need
Challenges with traditional oncology data sources
Fragmented clinical data limits population definition: Building a clinically meaningful understanding of disease at the discovery stage requires combining multiple data types, including electronic health records, laboratory data, and genomic information, to accurately define patient populations and disease characteristics. In practice, these data are rarely available in a single, integrated source. Instead, teams must work across fragmented datasets with varying structures, completeness, and clinical depth.
Iterative cohort building slows early decisions: This work is typically performed through a combination of literature review, claims‑based analyses, structured EHR datasets, and targeted clinical data collection. Patient cohorts are defined iteratively, often across multiple rounds of analysis, as initial definitions prove too broad or not sufficiently clinically meaningful. As criteria are refined and assumptions revisited, analyses must be repeated, slowing progress and delaying confidence at a stage where timely decisions are critical.
Limited clinical granularity in traditional data sources: While claims data can provide scale, it does not allow precise patient identification when cohort definitions depend on disease severity, co‑morbidities, or molecular characteristics. More detailed sources, such as structured EHR datasets or patient records, can help refine cohorts but are often limited in scope, fragmented across care settings, or constrained by predefined data models.
Manual data harmonization increases cost and time to insight: These challenges are exacerbated in rare cancers or when targeted therapies are the focus of research and development. As a result, building a consistent view of the patient journey—from diagnosis through treatment and outcomes—requires combining and manually harmonizing multiple data sources. This process is time‑consuming, resource‑intensive, and often involves multiple internal teams and external partners. Repeated analyses and cohort refinements increase both cost and time to insight at a critical stage of development.
What early asset teams need during discovery
To move from iterative exploration to decision‑ready insight, early asset and translational teams need a way to generate a consistent, clinically grounded view of a cancer type without relying on fragmented analyses. At this stage, confidence in patient populations, treatment pathways, and opportunity size must be established early, often before comprehensive real‑world understanding is available.
A single, well‑defined patient population
This requires working from a single, well‑defined patient population rather than continuously redefining cohorts across multiple datasets. A consistent patient population is critical to support reliable estimates of patient numbers, opportunity size, and targeting assumptions at an early stage of development.
Longitudinal visibility across the patient journey
Teams must be able to follow patients longitudinally, from diagnosis through treatment and outcomes, without manual reconstruction of patient journeys across fragmented data sources. Longitudinal visibility is essential to understand disease progression and real‑world treatment patterns.
Comparable insight across populations and geographies
Insights must be comparable across populations and geographies to understand variation in clinical practice, treatment patterns, and outcomes. This enables teams to identify where unmet need is most significant and where discovery and development efforts should be focused.
Streamlined access and analysis
In practice, teams often rely on multiple external partners to access claims, clinical, and genomic datasets. This results in separate contracts, misaligned timelines, inconsistent cohort definitions, and significant effort required to reconcile analyses across sources. Streamlining access and analysis reduces iteration and enables faster, evidence‑based discovery decisions.
These requirements define what is needed to move discovery‑stage oncology programs from fragmented analysis to confident decision‑making. Without a consistent patient population, longitudinal visibility, cross‑geography comparability, and streamlined workflows, teams are forced to advance with partial or uncertain evidence — precisely at the point where early decisions have the greatest downstream impact.
Grounding discovery decisions in real‑world patient evidence
At BC Platforms, we enable early asset and translational teams to build a clinically grounded understanding of cancer at the discovery stage, where decisions on patient populations, opportunity size, and development strategy must be made with limited visibility.
By replacing fragmented data sourcing and reconciliation with a single, integrated approach, teams can move more efficiently from exploration to decision‑ready insight.
Global, clinically rich multi‑modal oncology data
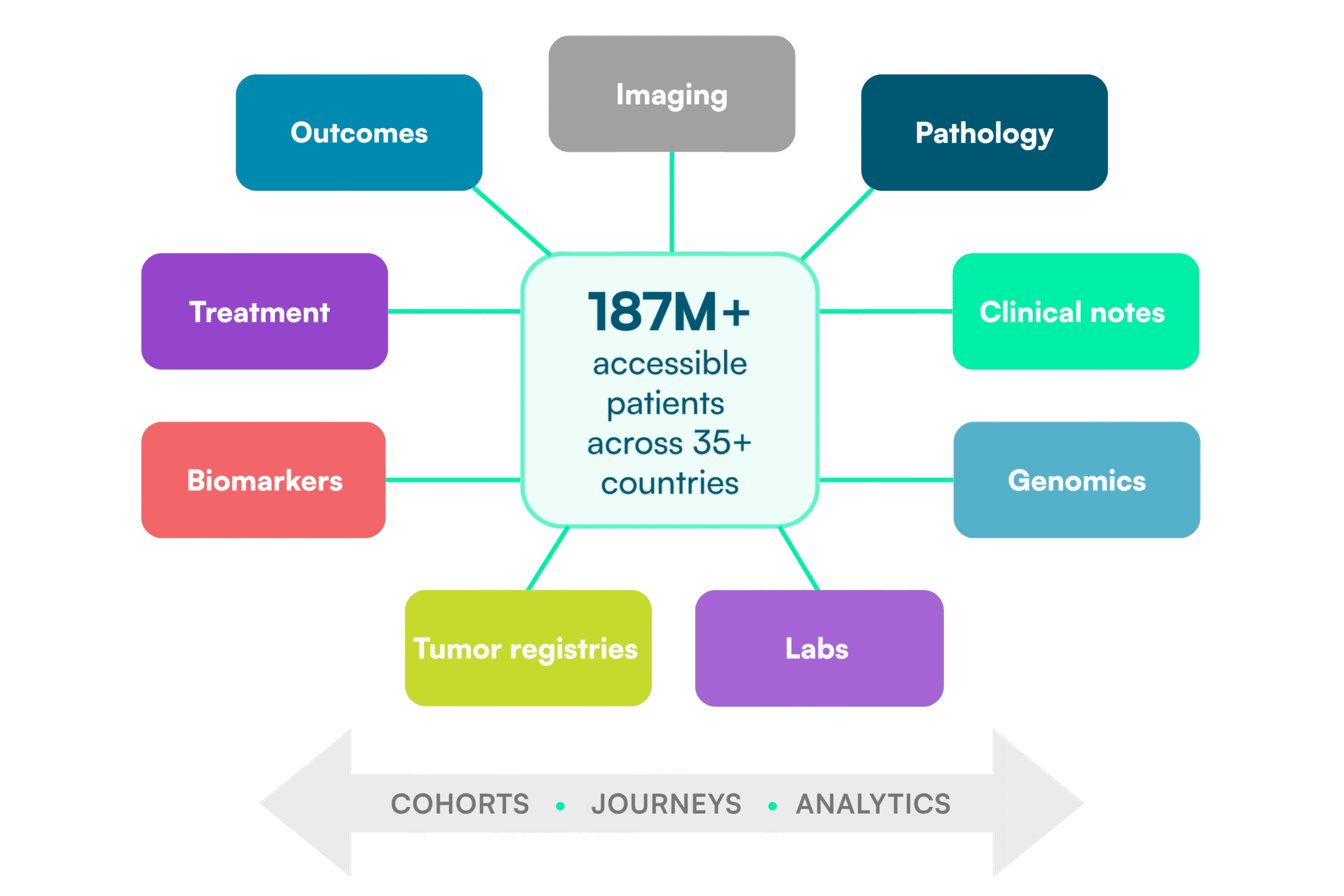
Rather than sourcing and reconciling data across multiple vendors, teams access clinically rich, multi‑modal patient datasets curated to address specific research needs. These datasets are created through our global data partner network, spanning more than 150 partners across 35+ countries and providing access to over 187 million patient lives, with the majority sourced outside the United States.
Custom oncology cohorts built from a single patient population
Based on defined patient inclusion and exclusion criteria, relevant data are selected and harmonized into research‑ready datasets that combine structured and unstructured sources, including electronic health records, laboratory data, imaging, and genomic information. This supports consistent cohort definitions across analyses and is particularly critical in oncology, where patient populations are defined by multiple clinical and biological factors.
Longitudinal patient‑level analysis in a trusted research environment
Patient data can be analyzed longitudinally, from diagnosis through lines of therapy and outcomes, providing a comprehensive view of real‑world disease management and access to clinically relevant endpoints. All analyses are conducted within BC Mosaic, our TRE, where de‑identified patient‑level data can be securely analyzed using integrated tools in a privacy‑preserving workspace aligned with regulatory frameworks such as GDPR and HIPAA.
These capabilities enable early asset teams to work from a single, longitudinal, and analytically consistent foundation, reducing iteration and supporting earlier, more confident decisions on patient targeting, opportunity assessment, and development strategy.
Real‑world example
Building a clinically grounded understanding of gastric cancer
An early asset team within a top 20 global pharmaceutical company developing multiple gastric cancer therapies requires a clearer understanding of how the disease is diagnosed, treated, and progresses in real‑world clinical practice to inform discovery‑stage decisions and support early financial forecasting.
Leveraging BC Platforms’ global patient network, a custom dataset is sourced from five leading European gastric cancer centers of excellence, selected in collaboration with the customer. The dataset combines clinically rich, multi‑modal data, including electronic health records and available genomic information, and is harmonized to address the team’s specific research questions.
Using a secure TRE housing de‑identified patient‑level data, descriptive and longitudinal analyses are conducted, including:
Estimation of diagnosed incidence and prevalence to quantify opportunity size and support early forecasting
Characterization of patient populations at diagnosis, including demographics, disease severity, co‑morbidities, and molecular testing where available
Analysis of treatment pathways to understand lines of therapy and variation across care settings
Time‑to‑event analyses for key clinical endpoints, including overall survival
These analyses provide a detailed, multi‑dimensional view of gastric cancer across care settings, enabling the team to refine its understanding of patient sub‑populations and treatment patterns and use this evidence to guide target population definition, development prioritization, and early asset strategy.
BC Platforms addresses the structural challenges of discovery‑stage evidence generation, where teams often rely on fragmented datasets, multiple vendors, and iterative analyses to answer foundational questions about disease.
By enabling teams to work from a single, consistent analytical foundation, we reduce operational complexity, avoid conflicting cohort definitions, and eliminate repeated rework across analyses. Access to a global network of clinically rich datasets, with strong representation of ex‑US populations, supports a more representative understanding of oncology practice across geographies, treatment patterns, and patient sub‑groups.
Combined with data harmonization and scalable analytics, this approach enables teams to move from fragmented exploration to decision‑ready insight with less time, lower operational burden, and greater confidence in the evidence.
Conclusion
The approach outlined here enables early asset and translational teams to generate real‑world evidence from clinically rich real‑world data, supporting oncology discovery and early development decisions.
By working from consistent, longitudinal patient‑level data rather than fragmented analyses, teams can define clinically relevant patient populations, quantify epidemiology and opportunity size, and understand real‑world treatment pathways and outcomes across geographies.
This supports earlier, evidence‑based decisions on target populations, development strategy, and prioritization while reducing iteration, operational burden, and uncertainty at a critical stage of drug development.
Want to understand what’s possible for your research program?
Talk with our team about your discovery‑stage questions — whether you’re defining patient populations, assessing opportunity size, or exploring real‑world treatment pathways using clinically rich data.